Proactive cache warming in a microservice-based architecture
With the microservice architecture style, services and their data are contained within a single bounded context. This architectural decision helps us to develop and deploy changes in one business unit fast and independent of other services in our system.
However, collecting and analyzing data from multiple services can be slow and much more complex than in a typical monolithic service where the caller has access to data from a single big database system.
Let’s look at an example: A web application for ordering items with a page that displays information about the most recent orders in a company.
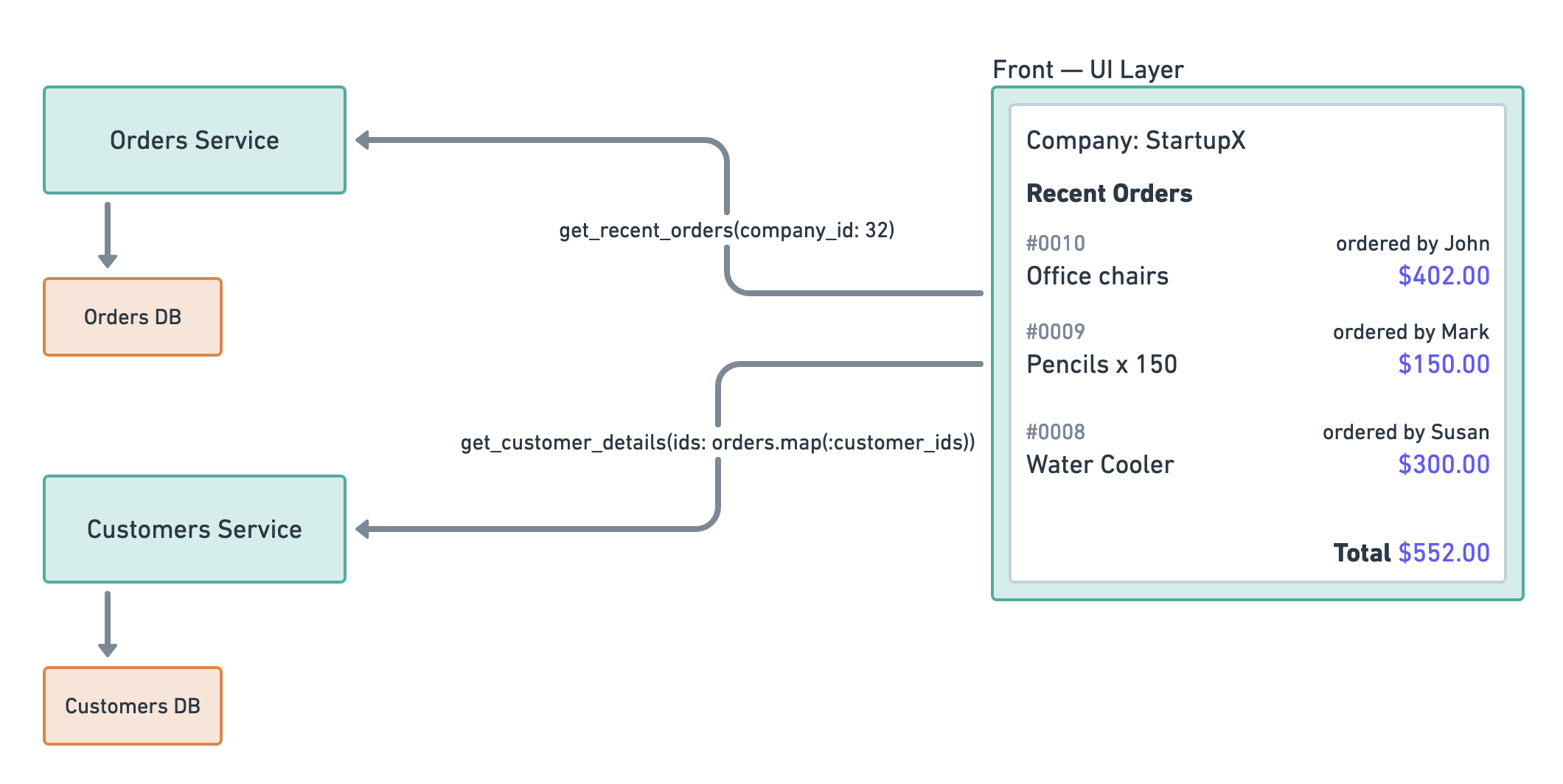
We will focus on the front service from the above architecture. More specifically, on its recent orders controller action.
def recent_orders(company_id)
orders = OrdersService.get_recent_orders(company_id)
customer_ids = orders.map(&:customer_ids)
customers = CustomerService.get_customer_details(customer_ids)
render_page(orders, customers)
end
Our next challenge is how to make this page fast.
Let’s assume for the sake of the argument that both the Orders Service and the Customer Services take around 200ms to respond and that we don’t have any viable way of making these response times faster.
To render the page, we need to wait 200ms for the Orders Service, then 200ms for the Customers Service, and finally, we need some time to generate the HTML page, 100ms. The minimum time to render the page is 500ms, which is relatively slow.
Caching is a standard tool that we use to make slow things faster. Key/Value memory stores like Redis can easily support 1ms response times if we figure out how to use it effectively.
Let’s explore some caching strategies.
Time-to-live based caching
A simple-to-implement caching strategy is a time-based one. This strategy renders the page and keeps it in the cache for a given amount of time.
CACHE_EXPIRES_IN = 1.hour
def recent_orders(company_id)
key = cache_key(company_id)
cached_page = Cache.find(key)
if cached_page.present?
cached_page
else
content = full_render(company_id)
Cache.store(key, content, ttl: CACHE_EXPIRES_IN)
content
end
end
def cache_key(company_id)
"recent_orders_page_#{company_id}"
end
def full_render(company_id)
orders = OrdersService.get_recent_orders(company_id)
customer_ids = orders.map(&:customer_ids)
customers = CustomerService.get_customer_details(customer_ids)
render_page(orders, customers)
end
This strategy can be the ideal one when the domain of the problem is time-bound. For example, if the page would display orders processed for the previous day instead of listing all the most recent ones.
The most significant downside is that the page will not refresh its content even if the system receives new orders. The page will be fast but stale.
Signature-based caching
We can use this information to optimize our rendering function. Another way to improve the speed of our page is to fetch some minimal amount of data that can signal to our system if our cached value is stale or usable.
Let’s assume that in the above example, the order processing system has an additional endpoint that can tell us the timestamp of the last processed order by a given company in 100ms.
We can use this information to optimize our rendering function.
def recent_orders(company_id)
last_order_at = OrdersService.get_last_order_timestamp(company_id)
key = cache_key(company_id, last_order_at)
cached_page = Cache.find(key)
if cached_page.present?
cached_page
else
content = full_render(company_id)
Cache.store(key, content, ttl: CACHE_EXPIRES_IN)
content
end
end
def cache_key(company_id, last_order_at)
"recent_orders_page_#{company_id}_#{md5(last_order_at)}"
end
def full_render(company_id)
orders = OrdersService.get_recent_orders(company_id)
customer_ids = orders.map(&:customer_ids)
customers = CustomerService.get_customer_details(customer_ids)
render_page(orders, customers)
end
The above implementation makes sure that we never have a stale state on the page. However, the performance gains are not so good as in our previous iteration.
If we have a cache hit, the performance will be 100ms as it takes this long to fetch the timestamp of the last order.
If we have a cache miss, the performance will be worse than it would be without caching. We will need 100ms to find the timestamp of the last order, plus the 500ms duration for the full page render.
Event-based caching
In both of the previous implementations, the core problem was how and when to clear the cached values. It turns out it is pretty hard to deduce this on the client-side.
One strategy common in distributed systems is to use events to propagate information about state changes. We can use this architecture to have a clear signal of when to clear our cache.
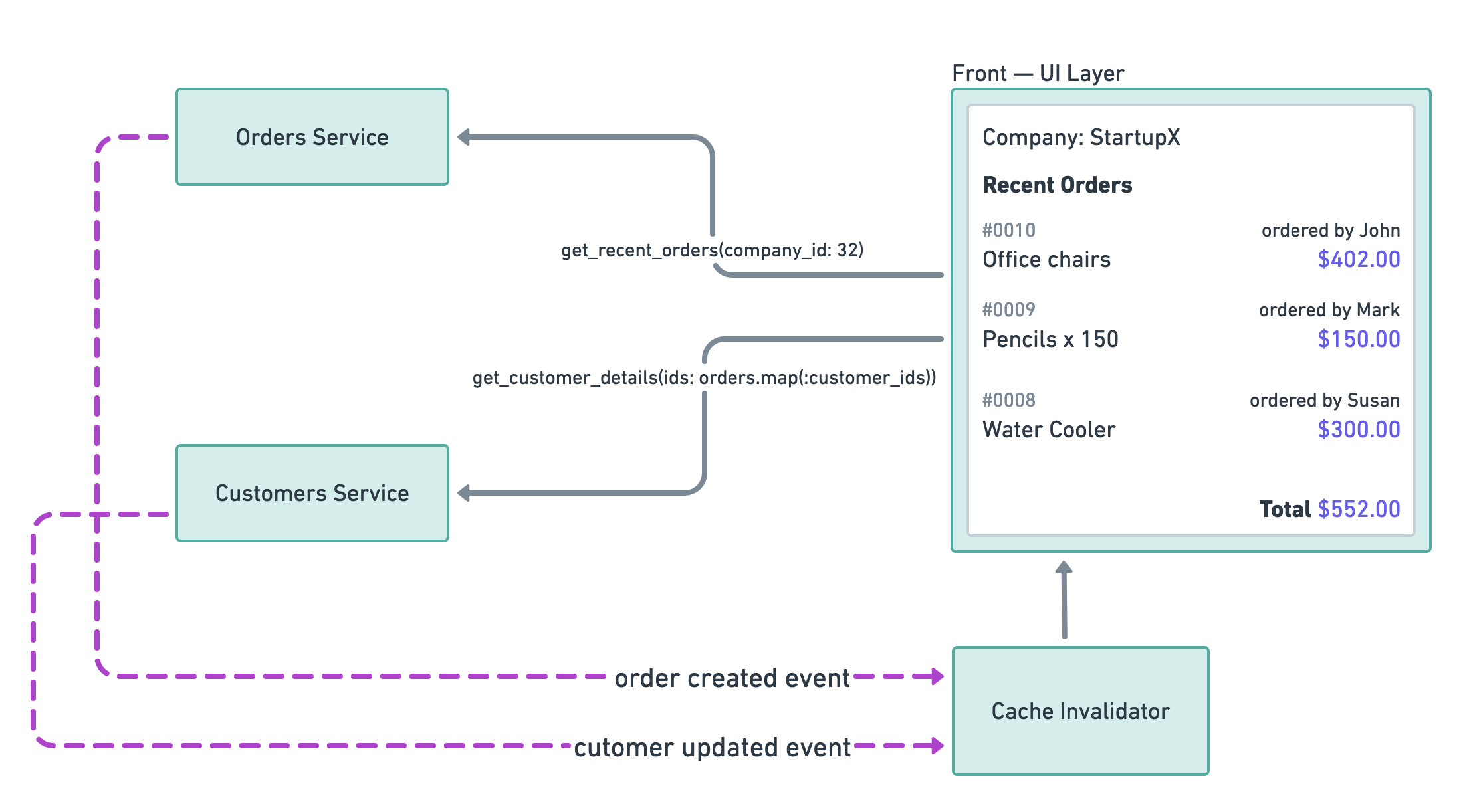
In this architecture, both the order processing service and the customer service are publishing events when their datasets change. The cache invalidator then listens to those events and clears the data from the UI layer’s cache.
def recent_orders(company_id)
key = cache_key(company_id)
cached_page = Cache.find(key)
if cached_page.present?
cached_page
else
content = full_render(company_id)
Cache.store(key, content)
content
end
end
subscribe("orders_service", "order-created") do |event|
key = cache_key(event.company_id)
Cache.clear(key)
end
subscribe("customers_service", "customer-updated") do |event|
key = cache_key(event.company_id)
Cache.clear(key)
end
We get pretty fast response times and up-to-date content in the cache. Neat!
If we have a cache hit, we can respond under 1ms, the amount of time it takes to fetch the data from the cache.
If we have a cache miss, we can respond in 500ms, the amount of data it takes to have a full page render.
The event-based cache invalidation is better in both cases from the signature-based caching solution we explored in the previous section.
Event-based proactive caching
We had a 1ms response for cached pages in that last section and 500ms for when the page wasn’t cached. Can we do better?
One approach that can guarantee a fast (1ms) response is to utilize proactive caching, meaning to prepare the page cache before the customers load it for the first time.
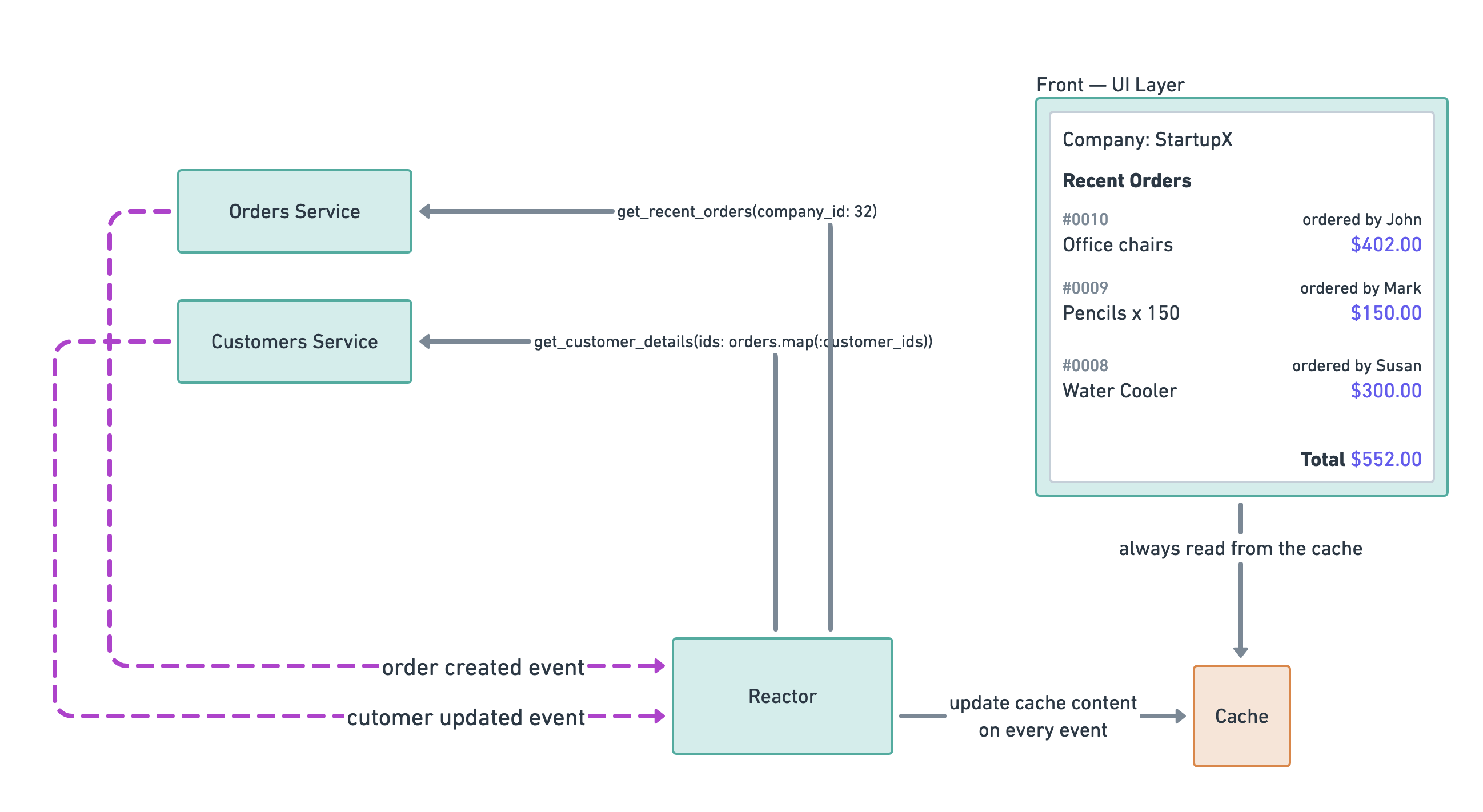
In this architecture, the UI layer always reads responses from the cache, meaning that it can guarantee a fast response time for both first visits and repeated visits to the page.
The reactor maintains the cache’s content, a subsystem in the UI layer that reacts to various events in the system and recalculates the cached content.
def recent_orders(company_id)
key = cache_key(company_id)
cached_page = Cache.find(key)
return cached_page
end
subscribe("orders_service", "order-created") do |event|
key = cache_key(event.company_id)
new_content = full_render(company_id)
Cache.store(key, new_content)
end
subscribe("customers_service", "customer-updated") do |event|
key = cache_key(event.company_id)
new_content = full_render(company_id)
Cache.store(key, new_content)
end
Let’s analyze this pattern. What are the shortcomings of this caching approach?
On the pros side, this caching approach can guarantee us fast response times for every page visit.
On the cons side, the reactor might be caching pages that our customers rarely visit, which leads to lots of busywork in our system. We might prepare and crunch an enormous amount of unused data.
The storage size can also drastically increase when we start using this approach as we are no longer storing only visited pages but all the pages in the cache.
If your number one priority is speed, the added storage and architectural complexity could be acceptable; otherwise, you might be crunching data needlessly. Choose carefully.
Caching is complicated, even more so in distributed systems.
At SemaphoreCI, we use event-based proactive caching to make our UI layer fast. Over the years, we faced many challenges while using this system, including race conditions and high queue processing latency. However, while these problems were challenging, we are still happy with this architectural choice even after several years in production.
Here are some great resources for further reading: